AKT基于上下文的知识追踪代码及原理讲解 |
您所在的位置:网站首页 › corrected 文件 › AKT基于上下文的知识追踪代码及原理讲解 |
AKT基于上下文的知识追踪代码及原理讲解
|
这篇文章主要是用来帮助初学者(也包括我自己)梳理框架,以及AKT代码是怎样实现的,我觉得我的想法不确定的地方,或者我也存在问题的地方我会进行标红,并且标上序号,大家在评论区一起讨论,取长补短,一起进步,希望大家不吝赐教!!!! 在AKT代码中主要需要看这五个文件 目录 prepare_dataset.ipynb 外层AKT.py文件 load_data.py 回到外部的AKT.py EduKTM包里面的AKT文件 loss函数指定 评价指标auc调用 评价指标acc调用 train_one_epoch
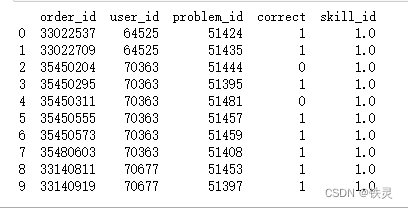
看代码时也是有顺序的,这五个文件应该先看prepare_dataset.ipynb这个文件,即先看他是怎么处理数据的,将数据处理成什么样子,这里即使不明白AKT的构建也没关系,只是在处理数据 。 prepare_dataset.ipynb.ipynb文件是jupyter notebook的文件形式,和.py文件之间互相调用是没有任何问题的,但是在jupyter notebook中运行的是.ipynb文件,在pycharm中运行的是.py文件,在起始的运行文件必须符合软件所需要的文件形式,那么怎么解决,,最简单方法是新建一个.py文件,然后将.ipynb文件里面的内容粘贴到.py文件中(反过来也同理)。#1.这里还有其他方法吗? # -*- coding: utf-8 -*- from EduData import get_data get_data("assistment-2009-2010-skill", "../../data")这里的EduData是发布过的一个包,没有的话需要 pip install一下 这个EduData的具体内容可以查看这个文档https://edudata.readthedocs.io/en/latest/tutorial/zh/DataSet.html 上面就是下载assistment-2009-2010-skill数据集,并且保存在相对路径为../../data的文件夹中 # -*- coding: utf-8 -*- import random import pandas as pd import tqdm data = pd.read_csv( '../../data/2009_skill_builder_data_corrected/skill_builder_data_corrected.csv', usecols=['order_id', 'user_id', 'skill_id', 'problem_id', 'correct'] ).dropna(subset=['skill_id', 'problem_id'])读取文件中,只用了其中的五个属性,并且对于skill_id和problem_id为空的数据去掉 用pd.read_csv读取的数据类型为dataframe 展示一下 print(data.readhead(10))
输出 number of skills: 123 number of problems: 17751这一步是将所有的skill和problem进行重新编号,但其实他们本身是有编号的,但是从上面的数据展示中可以看到有一个problem_id是51424,而总的problem数是17751,所以他的编号并不是传统意义上的从0或1开始编号,其实这样也不影响这种编号的使用,问题在于,在embedding或者one-hot的时候,是从0开始的,这样就会产生大量使用不到的参数或者one-hot的长度会大量增加。 所以对其进行了重新编号 def parse_all_seq(students): all_sequences = [] for student_id in tqdm.tqdm(students, 'parse student sequence\t'): student_sequence = parse_student_seq(data[data.user_id == student_id]) all_sequences.extend([student_sequence]) return all_sequences def parse_student_seq(student): seq = student.sort_values('order_id') s = [skills[q] for q in seq.skill_id.tolist()] p = [problems[q] for q in seq.problem_id.tolist()] a = seq.correct.tolist() return s, p, a # [(skill_seq_0, problem_seq_0, answer_seq_0), ..., (skill_seq_n, problem_seq_n, answer_seq_n)] sequences = parse_all_seq(data.user_id.unique()) print(len(data.user_id.unique()))这段代码的的读的顺序应该是:倒数第二行sequences=、再到parse_all_seq函数 将不同学生的信息分开,并将每个学生的信息分成三条存储,分别是学生所做知识点skill序列、学生所做题目problem序列以及对应的回答正误序列 all_sequences.extend([student_sequence]) 最后将一个学生的三条数据已列表的形式储存在sequence中 def train_test_split(data, train_size=.7, shuffle=True): if shuffle: random.shuffle(data) boundary = round(len(data) * train_size) return data[: boundary], data[boundary:] train_sequences, test_sequences = train_test_split(sequences)将构建好的sequence以7:3的比例划分成训练集和测试集 def sequences2l(sequences, trgpath): with open(trgpath, 'a', encoding='utf8') as f: for seq in tqdm.tqdm(sequences, 'write into file: '): skills, problems, answers = seq seq_len = len(skills) f.write(str(seq_len) + '\n') f.write(','.join([str(q) for q in problems]) + '\n') f.write(','.join([str(q) for q in skills]) + '\n') f.write(','.join([str(a) for a in answers]) + '\n') # save triple line format for other tasks sequences2l(train_sequences, '../../data/2009_skill_builder_data_corrected/train_pid.txt') sequences2l(test_sequences, '../../data/2009_skill_builder_data_corrected/test_pid.txt')将训练数据和测试数据写入文本进行存储 在原来的基础上在三条数据的基础上增加了第四条数据,该学生练习的长度(因为每个学生的做题不同,所以每组数据的长度也不同),每个学生的每组数据以列表形式存储,并且类表中的元素了类型为str,列表与列表之间用’,‘分割,学生与学生之间没有分割标记(应该会根据行数进行区分) 外层AKT.py文件剩下的文件是包含与被包含的关系,或者说是调用与被调用的关系,所以会交叉阅读 # coding: utf-8 # 2021/8/5 @ zengxiaonan from load_data import DATA, PID_DATA import logging from EduKTM import AKT batch_size = 64 model_type = 'pid' n_question = 123 n_pid = 17751 seqlen = 200 n_blocks = 1 d_model = 256 dropout = 0.05 kq_same = 1 l2 = 1e-5 maxgradnorm = -1load_data是自建的一个模块,具体应用后面会讲 logging 是python库,用于输出日志的,但这个地方没有这个也完全没有影响。 比如说logging的debug功能,这篇文章里的示例内容 https://blog.csdn.net/Nana8874/article/details/126041032 import logging # 配置logger并设置等级为DEBUG logger = logging.getLogger('logging_debug') logger.setLevel(logging.DEBUG) # 配置控制台Handler并设置等级为DEBUG consoleHandler = logging.StreamHandler() consoleHandler.setLevel(logging.DEBUG) # 将Handler加入logger logger.addHandler(consoleHandler) logger.debug('This is a logging.debug')输出 This is a logging.debug完全不如pycharm的debug功能好吧,这里指定了debug时出现的语句,不明白这样的debug有什么用,2、有谁可以教教我logging的真正用法 ok继续 # coding: utf-8 # 2021/8/5 @ zengxiaonan from load_data import DATA, PID_DATA import logging from EduKTM import AKT batch_size = 64 model_type = 'pid' n_question = 123 n_pid = 17751 seqlen = 200 n_blocks = 1 d_model = 256 dropout = 0.05 kq_same = 1 l2 = 1e-5 maxgradnorm = -1EduKtm是该代码中的自建包,里面有AKT模型的具体代码 if model_type == 'pid': dat = PID_DATA(n_question=n_question, seqlen=seqlen, separate_char=',') else: dat = DATA(n_question=n_question, seqlen=seqlen, separate_char=',') train_data = dat.load_data('../../data/2009_skill_builder_data_corrected/train_pid.txt') test_data = dat.load_data('../../data/2009_skill_builder_data_corrected/test_pid.txt')从上一段代码中可以看出,model_type被赋的值是pid 这里选用PID_DATA还是DATA已经是确定的了,PID_DATA对应着每个学生四条数据的情况,DATA对应着每个学生三条数据的情况。在prepare_dataset中(前面)已经将每个学生的数据存储为四条数据了。后面load_data.py文件中有具体的使用方法。 如果model_type(模型类型)为pid,那么调用load_data包里面的PID_DATA函数,那么现在去看load_data.py文件 load_data.py class PID_DATA(object): def __init__(self, n_question, seqlen, separate_char): self.separate_char = separate_char self.seqlen = seqlen self.n_question = n_question # data format # length # pid1, pid2, ... # 1,1,1,1,7,7,9,10,10,10,10,11,11,45,54 # 0,1,1,1,1,1,0,0,1,1,1,1,1,0,0 def load_data(self, path): f_data = open(path, 'r') q_data = [] qa_data = [] p_data = [] for lineID, line in enumerate(f_data): line = line.strip() if lineID % 4 == 2: Q = line.split(self.separate_char) if len(Q[len(Q) - 1]) == 0: Q = Q[:-1] # print(len(Q)) if lineID % 4 == 1: P = line.split(self.separate_char) if len(P[len(P) - 1]) == 0: P = P[:-1] elif lineID % 4 == 3: A = line.split(self.separate_char) if len(A[len(A) - 1]) == 0: A = A[:-1] # print(len(A),A) # start split the data n_split = 1 # print('len(Q):',len(Q)) if len(Q) > self.seqlen: n_split = math.floor(len(Q) / self.seqlen) if len(Q) % self.seqlen: n_split = n_split + 1 # print('n_split:',n_split) for k in range(n_split): question_sequence = [] problem_sequence = [] answer_sequence = [] if k == n_split - 1: endINdex = len(A) else: endINdex = (k + 1) * self.seqlen for i in range(k * self.seqlen, endINdex): if len(Q[i]) > 0: Xindex = int(Q[i]) + int(A[i]) * self.n_question question_sequence.append(int(Q[i])) problem_sequence.append(int(P[i])) answer_sequence.append(Xindex) else: print(Q[i]) q_data.append(question_sequence) qa_data.append(answer_sequence) p_data.append(problem_sequence) f_data.close() # data: [[],[],[],...] |
【本文地址】
今日新闻 |
推荐新闻 |